Votre entreprise utilise-t-elle MySQL ? Si oui, ce webinaire est pour vous !
Dans un monde où le piratage et le vol de données font l’actualité quotidienne, il est devenu vital de s’assurer que les données de vos clients et celles de vos employés sont protégées par les plus hauts standards de sécurité. Avec l’évolution constante des réglementations à travers le monde, il est important que votre entreprise puisse facilement évoluer afin de toujours pouvoir être en conformité.
Mais à vrai dire, il ne s’agit pas seulement de sécurité. Dans un monde extrêmement concurrentiel, il est particulièrement important que vos applications aient les meilleures performances et soient résilientes en étant hautement disponibles. Et lorsque des questions se posent ou que l’aide d’un expert est nécessaire, avoir accès aux ingénieurs MySQL les plus compétents – ceux qui écrivent le code – peut faire la différence.
MySQL Enterprise Edition offre tout cela et bien plus encore ! Découvrez comment dans ce webinaire et profitez de l’occasion pour poser vos questions directement à l’équipe MySQL.
HeatWave Machine Learning (ML) inclut tout ce dont les utilisateurs ont besoin pour créer, former, déployer et expliquer des modèles d’apprentissage automatique dans MySQL HeatWave, sans coût supplémentaire.
Dans ce webinaire vous apprendrez :
Ce qu’il faut pour commencer à utiliser HeatWave ML avec MySQL
Le fonctionnement de HeatWave ML
Quels algorithmes d’apprentissage automatique peuvent être utilisés avec HeatWave ML
Comment configurer des modèles d’apprentissage automatique avec vos données
Comment expliquer les résultats fournis par HeatWave ML
Ne manquez pas cette formidable opportunité et l’occasion de poser vos questions directement à l’équipe MySQL !
Comme tu le sais, MySQL est la base de données la plus populaire au monde. MySQL est également un élément majeur de la stratégie base de données des sites Web les plus fréquentés au monde, tels que Facebook, Twitter et YouTube. C’est également l’une des bases de données les plus faciles à utiliser, elle est donc parfaite pour les débutants.
Dans cette session, tu découvriras :
Quels sont les outils indispensables et où les télécharger
Les étapes pour installer et configurer votre serveur MySQL
Comment télécharger une base de données de test et exécuter les requêtes élémentaires
Comment éviter les pièges courants
Nous aborderons aussi les étapes pour créer et connecter des applications à ta base de données MySQL. Enfin, nous te montrerons comment facilement utiliser MySQL dans le Cloud.
Ce wébinaire se déroulera le mardi 3 mai 2022, à 10h CEST et c’est gratuit 🙂
Ne manque pas cette formidable opportunité et l’occasion de poser tes questions directement à l’équipe MySQL !
Pour ma part, je te parlerai des dernières innovations MySQL, plus spécifiquement de MySQL HeatWave qui est le seul service MySQL avec un accélérateur de requêtes en mémoire et qui en plus propose des capacité des Machine Learning intégrées… stupéfiant ! 🙂
Ma session « Profiter des services MySQL Dabatase et HeatWave sur Oracle Cloud Region Marseille » est à 15h10.
Maintenir la disponibilité de son application en cas de sinistre est très important pour les systèmes critiques de l’entreprise. Il est essentiel de mettre en place, dans le cadre d’un plan de reprise d’activité, une architecture robuste, hautement disponible, qui puisse maintenir le service en cas de panne ou de dommage des serveurs et de l’infrastructure informatique, même lorsque ceux-ci sont dans le Cloud.
Ce mardi 1 mars 2022, à 10h CEST, on va parler de ces sujets passionnants dans un contexte MySQL dans le Cloud.
Dans ce webinaire, nous verrons un exemple d’architecture de haute disponibilité pour la reprise après sinistre avec MySQL Database Service.
Nous verrons comment configurer les nœuds primaires et secondaires avec réplication automatique des données dans d’autres centres de données, et comment configurer le réseau, les tables de routage et les listes de sécurité.
Ne manquez pas cette formidable opportunité et l’occasion de poser vos questions directement à l’équipe MySQL !
L’Oracle Developer Week est une semaine (du 21 au 25 février 2022) consacrée au développement, rien que pour toi, ami développeur 🙂
Pas moins de 11 sessions en français et des ateliers sur les thèmes suivants :
Cloud Native
Microservices
Autoscaling
Kubernetes
Containers
Verrazzano
Streaming
Kafka
Java
MySQL
Machine Learning
Oracle Cloud Infrastructure
…
Toutes ces sessions sont animées par des experts, ingénieurs, développeurs, architectes expérimentés dans le développement d’applications critiques et exigeantes.
Dans cette session, animée par Marc et moi, tu apprendras comment déployer de manière optimale une application Java avec une base de données MySQL dans OCI, le cloud d’Oracle. Je te présenterai MySQL Database Service, le service PaaS MySQL d’OCI, nous explorerons ses capacités. Ensuite, avec Marc, une application Java sera conteneurisée et déployée dans Oracle Kubernetes Engine (OKE).
Cette session a lieu le vendredi 25 février 2022 à 11h CET.
Ces solutions, créées et supportées par l’équipe MySQL, sont en quelques années devenus les nouveaux standards sur le marché. Elles sont utilisées par de nombreuses entreprises, grandes et petites, pour leurs applications les plus critiques.
En ce qui concerne le plan de continuité d’activité, une toute nouvelle solution a été implémentée: MySQL InnoDB ClusterSet.
Ce mardi 18 janvier 2022, à 10h CEST, on en parle en direct dans un webinaire dédié à la protection de ton architecture MySQL.
Cette présentation couvrira les différentes architectures de base de données pour la haute disponibilité et la continuité d’activité.
Elle mettra en évidence les meilleures pratiques, développées avec de nombreuses entreprises et t’ aidera à choisir les bonnes solutions en fonction de tes besoins.
Objectif cloud, c’est 6 sessions techniques d’initiation au Cloud Oracle (OCI), 6 wébinaires d’1h30 qui te donnent l’opportunité de te former gratuitement aux technologies et aux bonnes pratiques de l’informatique dématérialisé.
Au programme :
Contenu théorique
Démonstrations interactives
Exercices pratiques avec un compte d’essai gratuit au Cloud Oracle OCI
Le titre de la session 5 est : Comment accélérer le déploiement de vos applications cloud native ?
Les technologies abordées sont: Opérateur MySQL pour Kubernetes, MySQL Database Service, MySQL HeatWave, Low Code APEX, Terraform, Ansible…
C’est donc le Mercredi 29 septembre 2021 de 10h – 11h30
Tu peux également rejoindre le groupe LinkedIn dédié à la série pour poser tes questions à nos experts et pour accéder aux replays et aux exercices pratiques : https://www.linkedin.com/groups/8987442/
Les vacances sont terminées :'( mais la bonne nouvelle est que la saison des wébinaires MySQL reprend \o/
Le premier sujet post-vacance est particulièrement intéressant, c’est la symbiose entre MySQL, Cloud, Big data(set) et performances extraordinaires… (et je pèse mes mots).
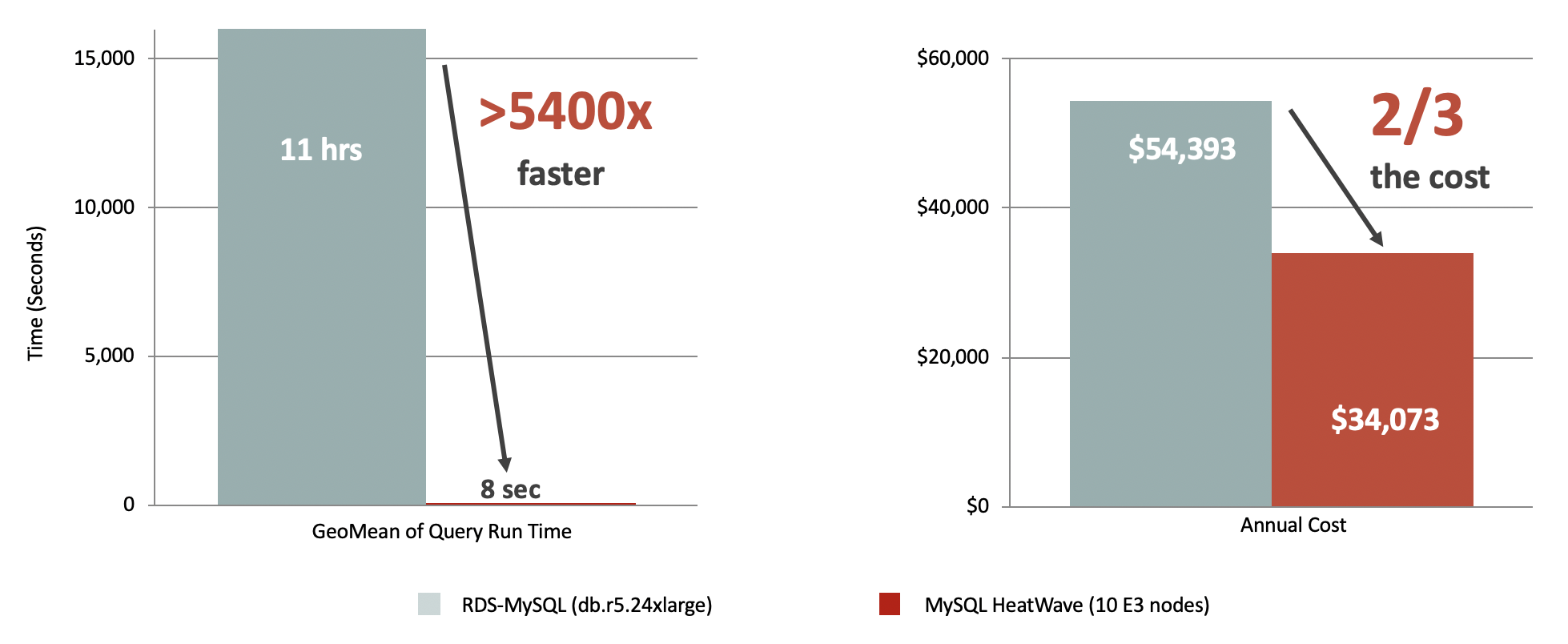
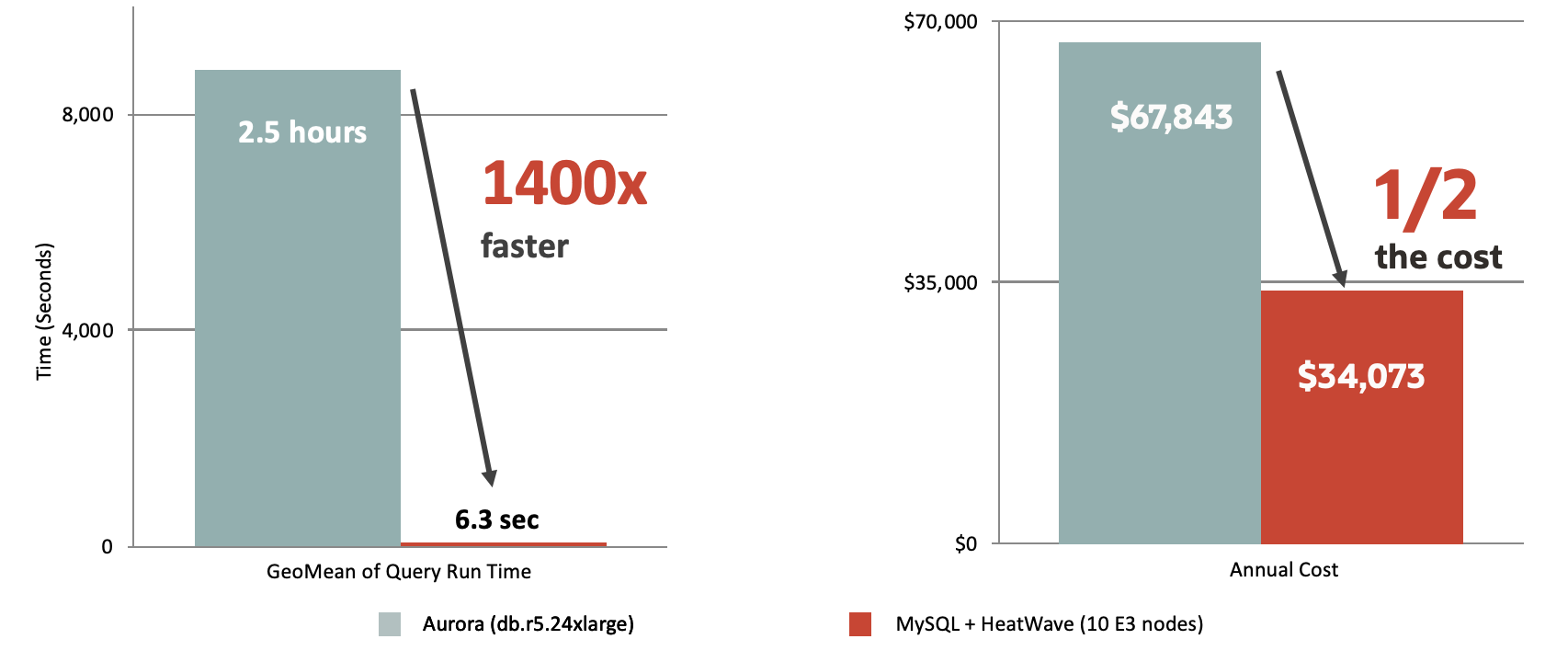
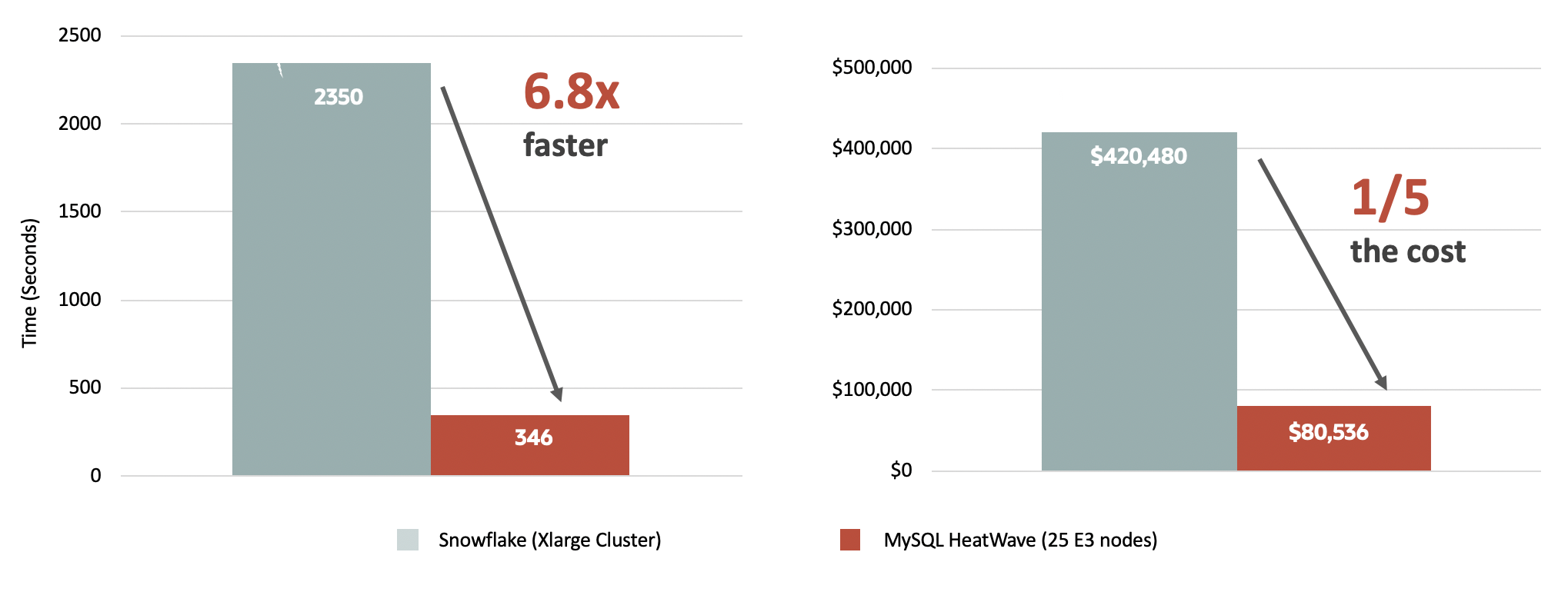
Le mot clé est MySQL HeatWave, l’accélérateur en mémoire de requêtes qui booste les performances.
En images ça donne…
MySQL Database Service with HeatWave vs. Amazon RDS: 4TB MySQL Database Service with HeatWave vs. Amazon Aurora: 4TB MySQL Database Service with HeatWave vs. Snowflake: 10TB
Tout simplement parce que c’est une superbe nouvelle pour l’écosystème MySQL et que ce mardi 28 septembre 2021, à 10h CEST, on en parle. Tu pourras également poser des questions.















{kind=link}
{kind=link}
{kind=link}