Automatic connection failover for Asynchronous Replication

TL;DR
Since MySQL 8.0.22 there is a mechanism in asynchronous replication that makes the receiver automatically try to re-establish an asynchronous replication connection to another sender, in case the current connection gets interrupted due to the failure of the current sender.
Asynchronous automatic connection failover automates the process of re-establishment of an asynchronous replication connection to another sender of sender list.
That means if a the source of a replica crashed, this replica will be able to automatically connect to another source.
One of the biggest interest is to improve Disaster Recovery (DR) architecture.
With this feature, a typical architecture is to have a 3 nodes asynchronous replication cluster.
2 primary nodes in active/passive mode (if you need active/active architecture use MySQL InnoDB Cluster) and the third one is connected to one of the primary, either for DR or for some specialized task like analytics for example.
So in case of unavailability of its primary – if the replication I/O thread stops due to the source stopping or due to a network failure – this replica will automatically connect to the other primary.
Another architecture is to use this asynchronous automatic connection failover feature with MySQL InnoDB Cluster.
Hey guess what? this is the topic of this tutorial and by the way, we will use some of the fanciest MySQL 8.0 features 🙂
Context
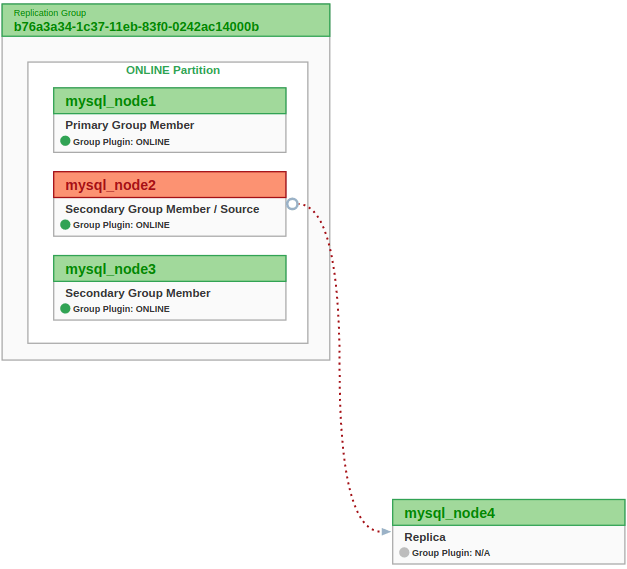
4 MySQL 8.0.22 instances :
– mysql_node1 : 172.20.0.11
– mysql_node2 : 172.20.0.12
– mysql_node3 : 172.20.0.13
These 3 are members of a MySQL Group Replication cluster.
I created a MySQL InnoDB Cluster (resources here and here).
I will not use MySQL Router in this tutorial.
– mysql_node4 : 172.20.0.14
It’s my replica.
It will be asynchronously connected to the Group Replication.
Because a picture is worth a thousand words, below is the architecture I want to achieve :

Graphs in this article are from MySQL Enterprise Monitor.
Current status
I’m using MySQL 8.0.22 :
$ mysqlsh root@mysql_node1:3306 --cluster
mysql_node1:3306 ssl JS> \sql SELECT VERSION();
+-----------+
| VERSION() |
+-----------+
| 8.0.22 |
+-----------+I have a 3 nodes Group Replication cluster up and running :
mysql_node1:3306 ssl JS>
cluster.status()
{
"clusterName": "ic1",
"defaultReplicaSet": {
"name": "default",
"primary": "mysql_node1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"mysql_node1:3306": {
"address": "mysql_node1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.22"
},
"mysql_node2:3306": {
"address": "mysql_node2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.22"
},
"mysql_node3:3306": {
"address": "mysql_node3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.22"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "mysql_node1:3306"
}Setup the replication user
Like you know, there are some preparation steps to be able to use MySQL Asynchronous Replication. If you’re not familiar with replication using GTID, please read this.
On the Group Replication primary – currently mysql_node1 – I setting up the asynchronous replication user:
mysql_node1:3306 ssl SQL>
CREATE USER 'repl'@'172.20.0.%' IDENTIFIED BY 'S3cr€tRepl' REQUIRE SSL;
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'172.20.0.%';Setup the clone user
The clone plugin is one of my favorite feature!
It permits cloning data locally or from a remote MySQL server instance.
Cloned data is a physical snapshot of data stored in InnoDB that includes schemas, tables, tablespaces, and data dictionary metadata.
The cloned data comprises a fully functional data directory, which permits using the clone plugin for MySQL server provisioning.
It’s a very convenient way to copy data from the source (the Group Replication) to the replica (mysql_node4).
Thanks to InnoDB Cluster the Clone plugin is already installed on the 3 members.
So on the primary member – currently mysql_node1 – I’ll create a dedicated clone user with the donor privileges for using and monitoring the clone plugin:
mysql_node1:3306 ssl SQL>
CREATE USER clone_user IDENTIFIED BY "S3cr€tClone";
GRANT BACKUP_ADMIN, EXECUTE ON *.* TO clone_user;
GRANT SELECT ON performance_schema.* TO clone_user;Note that I could have used the cluster administrator dedicated user instead of create a specialized clone user.
On mysql_node4, the future replica, I’ll create the same user but with the recipient privileges.
But before I’ll install the clone plugin and set the clone donor list:
mysql_node4:3306 ssl SQL>
INSTALL PLUGIN clone SONAME 'mysql_clone.so';
SET PERSIST clone_valid_donor_list = 'mysql_node1:3306,mysql_node2:3306,mysql_node3:3306';
CREATE USER clone_user IDENTIFIED BY "S3cr€tClone";
GRANT CLONE_ADMIN, EXECUTE ON *.* to clone_user;
GRANT SELECT ON performance_schema.* TO clone_user; Clone a MySQL instance
Now we have everything all set to create the replica from a member of the group.
On the future replica – mysql_node4 – we can now run the clone instance command:
mysql_node4:3306 ssl SQL>
CLONE INSTANCE FROM 'clone_user'@'mysql_node1':3306 IDENTIFIED BY 'S3cr€tClone';If you want to monitor the cloning progress run the following query:
mysql_node4:3306 ssl SQL>
SELECT
STATE,
CAST(BEGIN_TIME AS DATETIME) AS "START TIME",
CASE WHEN END_TIME IS NULL THEN LPAD(sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(now()) - UNIX_TIMESTAMP(BEGIN_TIME))), 10, ' ')
ELSE
LPAD(sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(END_TIME) - UNIX_TIMESTAMP(BEGIN_TIME))), 10, ' ') END AS DURATION
FROM performance_schema.clone_status;When the cloning is over, the MySQL instance must be restarted (that will normally happen automatically).
After the restart, you can verify that the clone completed successfully with the queries below:
mysql_node4:3306 ssl SQL>
SELECT
STATE,
ERROR_NO,
BINLOG_FILE,
BINLOG_POSITION,
GTID_EXECUTED,
CAST(BEGIN_TIME AS DATETIME) as "START TIME",
CAST(END_TIME AS DATETIME) as "FINISH TIME",
sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(END_TIME) - UNIX_TIMESTAMP(BEGIN_TIME))) AS DURATION
FROM performance_schema.clone_status \Gand:
mysql_node4:3306 ssl SQL>
SELECT
STAGE,
STATE,
CAST(BEGIN_TIME AS DATETIME) as "START TIME",
CAST(END_TIME AS DATETIME) as "FINISH TIME",
LPAD(sys.format_time(POWER(10,12) * (UNIX_TIMESTAMP(END_TIME) - UNIX_TIMESTAMP(BEGIN_TIME))), 10, ' ') AS DURATION
FROM performance_schema.clone_progress;Add the replica
First I will setup the configuration information for a replication source server to the source list for a replication channel.
To do that we use the function: asynchronous_connection_failover_add_source
Information needed are the replication channel name, the source server address, port and network namespace, and also the weight.
More information are available here.
For this tutorial I chose the following values:
- Channel name: autof
- Source server addresses: mysql_node1, mysql_node2, mysql_node3
- Source server port: 3306
- Source server network namespace: ” (empty)
- Weight: respectively: 50, 90, 90
mysql_node4:3306 ssl SQL>
SELECT asynchronous_connection_failover_add_source('autof', 'mysql_node1', 3306, '', 50);
SELECT asynchronous_connection_failover_add_source('autof', 'mysql_node2', 3306, '', 90);
SELECT asynchronous_connection_failover_add_source('autof', 'mysql_node3', 3306, '', 90);The replica’s source lists for each replication channel for the asynchronous connection failover mechanism can be viewed in the Performance Schema table replication_asynchronous_connection_failover.
mysql_node4:3306 ssl SQL>
SELECT * FROM performance_schema.replication_asynchronous_connection_failover;
+--------------+-------------+------+-------------------+--------+
| Channel_name | Host | Port | Network_namespace | Weight |
+--------------+-------------+------+-------------------+--------+
| autof | mysql_node1 | 3306 | | 50 |
| autof | mysql_node2 | 3306 | | 90 |
| autof | mysql_node3 | 3306 | | 90 |
+--------------+-------------+------+-------------------+--------+
To set the parameters that the replica server uses for connect to the source, we use the well known CHANGE MASTER TO statement.
You already know most of its clauses, so let’s only focus on some of them:
- SOURCE_CONNECTION_AUTO_FAILOVER : activates the asynchronous connection failover mechanism.
- MASTER_RETRY_COUNT & MASTER_CONNECT_RETRY : define the failover time. The default setting is… 60 days, probably not what you want :). So, you (most likely) should reduced the settings. e.g. 1 minute is respectively 20 and 3. (20 x 3 = 60)
- FOR CHANNEL : enables you to name which replication channel the statement applies to. The CHANGE MASTER TO statement applies to this specific replication channel.
Now let’s configure the replication:
mysql_node4:3306 ssl SQL>
CHANGE MASTER TO MASTER_USER='repl', MASTER_PASSWORD='S3cr€tRepl', MASTER_HOST='mysql_node2', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_SSL=1, SOURCE_CONNECTION_AUTO_FAILOVER=1, MASTER_RETRY_COUNT=3, MASTER_CONNECT_RETRY=5 FOR CHANNEL 'autof';Please note that my failover time in this tutorial is 15 seconds (3 x 5). Obviously the relevant setting depends on your needs. A longer duration will probably makes more sense in real life.
Then start the replication, on channel autof using START REPLICA:
mysql_node4:3306 ssl SQL>
START REPLICA FOR CHANNEL "autof";Status information of the replication can be seen with SHOW REPLICA:
mysql_node4:3306 ssl SQL>
SHOW REPLICA STATUS\G
*************************** 1. row ***************************
Replica_IO_State: Waiting for master to send event
Source_Host: mysql_node2
Source_User: repl
Source_Port: 3306
Connect_Retry: 5
...
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
...
Source_Retry_Count: 3
...
Auto_Position: 1
...
Channel_Name: autof
...Automatic connection failover
We have now configured our replication, with an InnoDB Cluster/Group Replication as a source and a standalone MySQL server as a replica.
Let’s see how the automatic connection failover works.
Restart the replica
I want to see the behavior after a restart of the replication.
State before the stop:
mysql_node4:3306 ssl SQL>
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3Stop the replication:
mysql_node4:3306 ssl SQL>
STOP REPLICA;
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: OFF
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3
After a while, start the replication:
mysql_node4:3306 ssl SQL>
START REPLICA;
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3Replica picks up where it left off… as you would have expected.
Short unavailability of the source
I want to see the behavior after a short unavailability of the source. I mean a duration lower than the failover threshold – connection_retry_interval x connection_retry_count – 15 seconds (5×3) in this example.
State before the stop of the source, mysql_node2:
mysql_node4:3306 ssl SQL>
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3… Stop mysql_node2 for 10 seconds …
State after the start of the source mysql_node2:
mysql_node4:3306 ssl SQL>
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3Well… nothing changed!
The unavailability of the source was not long enough to trigger the failover.
That is awesome to prevent non necessary failover.
Long unavailability of the source
I want to see the behavior after a longer unavailability of the source. I mean a duration greater than the failover threshold – connection_retry_interval x connection_retry_count – 15 seconds (5×3) in this example.
State before the stop of the source, mysql_node2:
mysql_node4:3306 ssl SQL>
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node2
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3… Stop mysql_node2 for 20 seconds …
mysql_node4:3306 ssl SQL>
SELECT
CHANNEL_NAME,
SERVICE_STATE,
HOST,
CONNECTION_RETRY_INTERVAL,
CONNECTION_RETRY_COUNT
FROM replication_connection_configuration
INNER JOIN replication_applier_status
USING (CHANNEL_NAME)
WHERE CHANNEL_NAME = 'autof'\G
*************************** 1. row ***************************
CHANNEL_NAME: autof
SERVICE_STATE: ON
HOST: mysql_node3
CONNECTION_RETRY_INTERVAL: 5
CONNECTION_RETRY_COUNT: 3
As expected, the asynchronous automatic connection failover took place. \o/
The new source is now mysql_node3, because it has a bigger weight than mysql_node1 (90 vs 50) and because it was available 🙂
Limitations
Please be aware that in 8.0.22 this feature lacks of some of the needed functionality to replace MySQL Router as means to replicate from an InnoDB Cluster/Group Replication cluster.
Things such as:
- does not automatically learn about new members or members that are removed
- does not follow the primary role, it stays connected to whatever host it was connected to
- does not follow the majority network partition
- does not care if a host is not part of the group any longer, as long as it can connect, it will
These limitations will be lifted in future versions.
This is a very nice feature starting with MySQL 8.0.22, useful for both MySQL Replication and MySQL Group Replication architectures.
And you know what? There is more to come 😉
Stay tuned!
References
- Switching Sources with Asynchronous Connection Failover
- Functions which Configure the Source List
- WL#12649: Automatic connection failover for Async Replication Channels – Step I: Automatic Connection Failover
- Clone: Create MySQL instance replica
- The Clone Plugin
- MySQL Replication
- MySQL Group Replication
- MySQL InnoDB Cluster
- Tutoriel – Déployer MySQL 8.0 InnoDB Cluster
- MySQL Enterprise Edition
Watch my videos on my YouTube channel and subscribe.
My Slideshare account (archive).
Thanks for using HeatWave & MySQL!

MySQL Cloud AI & Analytics Solutions Architect at Oracle
MySQL Geek, strong interest in data and AI, author, blogger and speaker
I’m an insatiable hunger of learning.
—–
Blog: www.dasini.net/blog/en/
Linkedin : www.linkedin.com/in/olivier-dasini
Speaker Deck: https://speakerdeck.com/freshdaz
SlideShare: www.slideshare.net/freshdaz
Youtube: https://www.youtube.com/channel/UC12TulyJsJZHoCmby3Nm3WQ
—–
[…] Automatic Asynchronous Replication Connection Failover […]
[…] Automatic Asynchronous Replication Connection Failover […]
hi, what about the features in MySQL 8.0.23 version? Are the limitations also the same as version 8.0.22? Thank You.
Hello,
They are some improvements in 8.0.23+
Please have a look to:
https://lefred.be/content/setup-dr-for-your-mysql-innodb-cluster/
and
https://mysqlhighavailability.com/asynchronous-replication-connection-failover-automatic-source-list/
And there is still more to come