Create a Cloud Backup with MySQL Enterprise Backup

MySQL Enterprise Edition customers have access to MySQL Enterprise Backup.
MySQL Enterprise Backup provides enterprise-grade backup and recovery for MySQL. It delivers hot, online, non-blocking backups on multiple platforms including Linux, Windows, Mac & Solaris.
https://www.mysql.com/products/enterprise/backup.html
Cloud backup is a strategy increasingly used in organizations. Send copies of your data to the cloud, can help you to prevent a devastating IT crisis and ensure business continuity.
Currently, MySQL Enterprise Backup supports the following types of cloud storage services:
- Oracle Cloud Infrastructure (OCI) Object Storage
- OpenStack Swift or compatible object storage services
- Amazon Simple Storage Service (S3) or compatible storage service
In this blog post I will use the OCI object storage, for obvious reasons 🙂 and also because it’s probably the best feature/price ratio choice.
Create a pre-authenticated request for a bucket
First we must create an OCI Pre-Authenticated Request (PAR) for a bucket.
Pre-authenticated requests provide a way to let users access a bucket or an object without having their own credentials, as long as the request creator has permissions to access those objects.
https://docs.cloud.oracle.com/en-us/iaas/Content/Object/Tasks/usingpreauthenticatedrequests.htm
You can create, delete, or list pre-authenticated requests using the Console, using the CLI, or by using an SDK to access the API.
Click here to see how to create a PAR.
If you use the console, you’ll have something like:
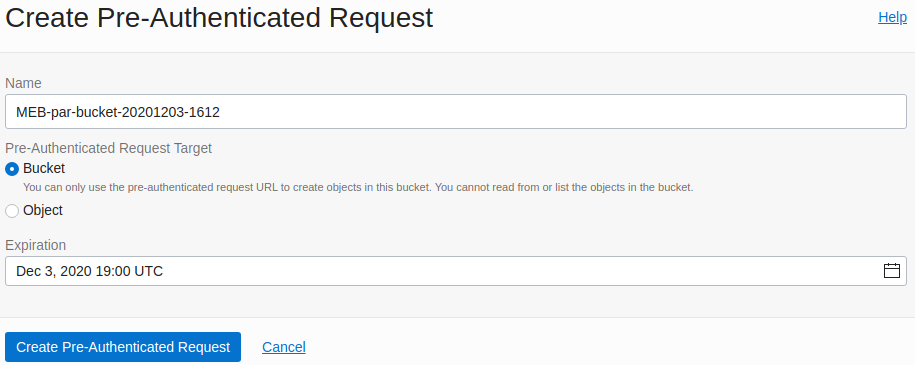
My Oracle Cloud Infrastructure Pre-Authenticated Request name is : MEB-par-bucket-20201203-1612

An URL is generated. It is very important to save it!
We’ll use it with MySQL Enterprise Backup.
I can also see my list of PARs in the console:

Create a Cloud Backup on Oracle Cloud Infrastructure Object Storage
I’m using MySQL Enterprise Backup 8.0.22.
The extra options to backup your data into OCI Object Storage are:
cloud-service : Cloud service for data backup or restoration.
Currently, there are 3 types of cloud storage services supported by mysqlbackup, represented by the following values for the option:
- OCI: Oracle Cloud Infrastructure Object Storage
- openstack: OpenStack Swift or compatible object storage services
- S3: Amazon Simple Storage Service (S3) or compatible storage service.
cloud-object : The storage object for the backup image.
Note that names of objects within the same bucket have to be unique.
cloud-par-url : The Pre-Authenticated Request (PAR) URL for OCI Object Storage.
For a backup to OCI Object Storage, it is the PAR URL for the storage bucket; for restore and other operations on an object stored on OCI, it is the PAR URL for the object.
Click here to find the complete list of cloud storage options (OCI, Amazon S3 & OpenStack Swift options).
In this article the values of these options are:
- cloud-service=OCI
- cloud-par-url=https://objectstorage.us-ashburn-1.oraclecloud.com/p/JL7k0DnNE8DTV<…snip…>_bucket-20200908-1001/o/
- cloud-object=myBck_20201203-1600.mbi
I assume your already know what to do before the first backup.
Let’s create the backup then:
$ mysqlbackup --defaults-file=/etc/mysql/my.cnf --backup-dir=/meb-tmp --with-timestamp --backup-image=- --cloud-service=OCI --cloud-par-url=https://objectstorage.us-ashburn-1.oraclecloud.com/p/JL7k0DnNE8DTV<...snip...>_bucket-20200908-1001/o/ --cloud-object=myBck_20201203-1600.mbi backup-to-image
MySQL Enterprise Backup Ver 8.0.22-commercial for Linux on x86_64 (MySQL Enterprise - Commercial)
Copyright (c) 2003, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Starting with following command line ...
<... snip ...>
-------------------------------------------------------------
Parameters Summary
-------------------------------------------------------------
Start LSN : 27229330944
End LSN : 27229334048
-------------------------------------------------------------
201203 16:51:48 MAIN INFO: Cloud operation completed.
mysqlbackup completed OK!Don’t forget the value “–” (dash) for backup-image parameter:
--backup-image=-
The backup is now completed and stored on the Oracle Cloud Infrastructure object storage bucket.

Restore a Backup from Oracle Cloud Infrastructure
Again, a Pre-Authenticated Request (PAR) URL for OCI Object Storage will be used.
This time we will use a PAR on an object with Read PAR privileges created before the restoration.
Using the console, after selecting my Bucket, I create a pre-authenticated request for an object:

The PAR target is Object
My object name is myBck_20201203-1600.mbi
An read only access type is sufficient : Access Type: Permit reads on the object
Et voilà!
My PAR is created

An URL is generated. It is very important to save it!
We’ll use it with MySQL Enterprise Backup.
Now we have all that is needed to restore with MySQL Enterprise Backup.
I assuming you already now how to restore a MySQL instance with MEB.
Thus in our context, to restore a single-file backup from an OCI Object Storage to a MySQL Server, we will use:
$ mysqlbackup --defaults-file=/etc/mysql/my.cnf --backup-image=- --with-timestamp --backup-dir=/meb-tmp --cloud-service=OCI --cloud-par-url=https://objectstorage.us-ashburn-1.oraclecloud.com/p/FvbPbq7oJAGP<...snip...>_bucket-20200908-1001/o/myBck_20201203-1600.mbi copy-back-and-apply-log
MySQL Enterprise Backup Ver 8.0.22-commercial for Linux on x86_64 (MySQL Enterprise - Commercial)
Copyright (c) 2003, 2020, Oracle and/or its affiliates. All rights reserved.
<...snip...>
201208 12:11:27 MAIN INFO: Apply-log operation completed successfully.
201208 12:11:27 MAIN INFO: Full Backup has been restored successfully.
201208 12:11:27 MAIN INFO: Cloud operation completed.
mysqlbackup completed OK! with 4 warningsThe restore is now completed.
As a side note, if you want to see the 4 warnings, take a look at the MEB logfile, located in the –backup-dir, meb-tmp in this article:
$ grep WARNING /meb-tmp/2020-12-08_11-59-58/meta/MEB_2020-12-08.11-59-58.log
201208 11:59:58 MAIN WARNING: If you restore to a server of a different version, the innodb_data_file_path parameter might have a different default. In that case you need to add 'innodb_data_file_path=ibdata1:12M:autoextend' to the target server configuration.
201208 11:59:58 MAIN WARNING: If you restore to a server of a different version, the innodb_log_files_in_group parameter might have a different default. In that case you need to add 'innodb_log_files_in_group=2' to the target server configuration.
201208 11:59:58 MAIN WARNING: If you restore to a server of a different version, the innodb_log_file_size parameter might have a different default. In that case you need to add 'innodb_log_file_size=50331648' to the target server configuration.
201208 12:11:27 MAIN WARNING: External plugins list found in meta/backup_content.xml. Please ensure that all plugins are installed in restored server.Nothing really serious in this context.
If you need more information, please click here.
The rest of the story is classic, restart your MySQL instance and you good to go 🙂
One more thing to know and to keep in mind, is that a cloud backup always uses one write thread.
In clear backup & restore duration could be much longer than for a local operation.
However, it is a good practice, when possible, to keep a local copy of the backup file.
It is usually easier and much faster to recover from a local location.
MySQL Enterprise Edition
MySQL Enterprise Edition includes the most comprehensive set of advanced features, management tools and technical support to achieve the highest levels of MySQL scalability, security, reliability, and uptime.
It reduces the risk, cost, and complexity in developing, deploying, and managing business-critical MySQL applications.
MySQL Enterprise Edition server Trial Download (Note – Select Product Pack: MySQL Database).

References
- MySQL Enterprise Backup
- MySQL Enterprise Backup User’s Guide (Version 8.0.22)
- Backing Up to Cloud Storage
- Restoring a Backup from Cloud Storage to a MySQL Server
- MySQL Enterprise Edition
- Oracle Cloud Infrastructure (OCI)
- Overview of Object Storage
- Using Pre-Authenticated Requests
Watch my videos on my YouTube channel and subscribe.
My Slideshare account (archive).
Thanks for using HeatWave & MySQL!